Мәтіндерді автоматты аударма жасау үшін, сөздердің емлесі программа үшін аса қажет. Түптеп келгенде, әліпби ауыстыруда ең алдымен, осындай сөздердің емлесін нақтылап алуымыз қажет. Бұл әсіресе, кирил қаріпті көптеген әдебиеттерді (мәтіндерді) автоматты жолмен латынға аудару үшін басты шешіп алатын мәселе. Әрі келешек жазу емлесін ұлттық дыбыстау жүйесіне бейімдеу өзекті мәселе.
Кирилл қарпіндегі мәтіндерді латын қарпіне аудару оп-оңай жүзеге асырылмайды. Өйткені әліпби ауыстыру бір әріптің орнына бір әріпті қоя салу емес, бұл лингвистикалық қана емес, саяси-әлеуметтік те реформа. Әсіресе, әліпби ауыстыру кезінде әр ұлттың бітім-болмысына, табиғатына сәйкес фонды беру қиынның қиыны болып табылады. Қазіргі 70 жылдан астам тарихы бар Қазақстандағы кирилл жазуын өзгерту, қоғамдық санаға сіңген таңбалық стереотитптерді өзгерту оңай емес. Кейбір таңбалар бұрыннан ағылшын пернетақтасында пайдаланып жүрген үйреншікті болып, көзшалымға жатық, қабылдауға жеңіл болса, кейбір таңбалар кездейсоқтық туғызып, қабылдауға, жаттауға қиындық тудырады. Сонымен қатар әліпбидегі қазақ тілінде бұрын-соңды кирилл қарпінде болмаған қос әріппен таңбалау тұстары да жазудың эстетикалық айшығына, орфограммалық тұрпатына, яғни көзшалымға сәтсіздік тудырады. Әліпбиден бөлек, жазуда тағы бір атқарылатын үлкен жұмыс – емле ережелерін жасау. Жаңа емле бұрынғы емлені латын қарпіне ауыстыра салу емес, ол бұрынғы емледегі кейбір кемшіліктер мен олқылықтардың орнын толтыру үшін және де кирилл қарпінің экспансиясы ықпалымен ұлттық кодтан айрылып бара жатқан орфограммаларды қайта қалпына келтіру үшін немесе ұлттық сөйлеу жүйесін нормалау үшін де қайта жаңғыртылып жасалуы қажет.
Жазу реформасын жүзеге асыруда әртүрлі әлеуметтік көзқарас туғызып жүрген күрделі мәселелердің бірі – кирилл қарпінде жазылған жазба әдебиеттерімізді жоғалтып аламыз ба деген қауіп. Қазіргі компьютерлік техниканың дамыған заманында бұл мәселенің шешімін табу көп қиындыққа түспейтіні белгілі. Арине, кітап түрінде қайта шығару сияқты шығындары болуы мүмкін, ал электронды нұсқада әдебиеттерді, жазба мұраларымызды сақтап қалуға мүмкіндік әбден бар. Мұны автоматты аударым жасау ісі деп атайды. Мұндай амал-әрекетті жүзеге асырушы бағдарламаны «конвертер» деп атайды. Кейде орысша «перекодировчик» те қолданады.
Кирилл қарпіндегі мәтіндерді латын қарпіне автоматты аударым жасайтын конвертерлер әріптің орнына әріпті ауыстыра салмайды. Егер олай етсек, қаншама көлемді әдебиеттеріміз емле ережелері ескерілмеген қате орфограммаланады. Қазіргі интернет сайттарында жүрген конвертер бағдарламаларының көпшілігі осылай емле ережелері ескерілмей жасалған деуге болады. Автоматты аударым жасауға арналған бағдарлама жасау ол тек программистің жұмысы емес, ол емле ережелерін жіті қадағалап отырған лингвистердің де жұмысы екендігін айту қажет. Лингвистердің қадағалуынсыз автоматты аударым жасайтын компьютерлік бағдарлама мәтіндерді дұрыс көшірім жасай алмайды. Осы мәселені сәтті шешу үшін Қолданбалы лингвистика бөлімі әліпби бекіту процесі кезеңінде әр жылдары әліпби нұсқаларына сәйкес конвертерларды жасап отыруды міндет етіп қойып отыр. 2017 жылы апострофпен жасалған компьютерлік бағдарламаны жасаған болатын. 2018-де соңғы акутқа негізделген жаңа әліпбимен қайта жасады. Бұл орайда конвертер жасаушы бағдарламашыға тілшілер тарыпынан мынадай лингвистикалық нұсқаулық (программаға арналған емле) дайындалады.
Бірінші қадам. Компьютерлік бағдарлама үшін ең алдымен кирилл және соған сәйкес латынша таңбалары көрсетілген кесте 1 беріледі.
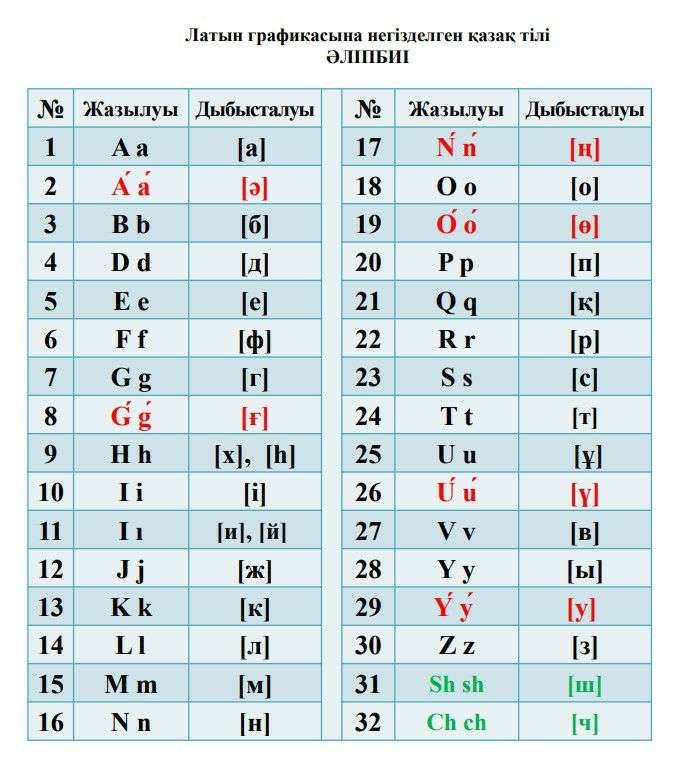
Жоғарыдағы суретте қазақ тіліндегі 32 әріп берілген, һ және х әріптері бір таңбамен таңбаланады – Hh. Сол сияқты әліпбиде кирилдегі И және Й әріптері латында бір ғана І әрпімен таңбаланған. Кестеде кирилдегі жалпы саны – 34 әріп тұр. Кирилдегі Ёё, Цц, Щщ, ь, ъ, Ээ, Юю, Яя әріптері таңбаланбаған. Жоғарыдағы 34 әріпке осы 8 әріпті қоссақ, кирилдегі 42 әріп болады.
Ш және ч әріптері диграфтармен берілген – Ш- Sh; Ch – Ч.
Мәтінде автоматты түрде кирилден латынға ауыстыру үшін кирилдегі барлық 42 әріптің қалай таңбаланатыны туралы нұсқаулық (емле) берілу керек. Сол үшін әліпбиде таңбаланбаған әріптерді латында қалай таңбаланатыны туралы да программаға арналған емле жасалады. Программаға арналған емле дайындау орфографиялық емле ережелеріне сүйенеді [1]. Біздің конвертор қазіргі орфографиялық топтың жасаған емле ережелерінің соңғы үлгісін басшылыққа алады.
Екінші қадам. Жоғарыда берілген латынға негізделген ұлттық әліпбиден басқа бұл әліпбиге енбеген 8 әріптің қалай таңбаланаты туралы нұсқаулық кесте 2 дайындалады.
Кесте 2 – Ұлттық әліпбиге енбеген 8 әріптің орфограммалануы
Ёё - Ее
Цц - S
пицца, ницца деген екі сөзде ғана - ts
Щщ - кірме сөздерде - sh
ал қазақтың байырғы сөздерінде, ащы, тұщы - shsh
Ээ - Ее
Юю - ɪý
Яя - ɪa
Кестеден көрініп тұрғандай, әліпбиде жоқ ь, ъ әріптері латын қаріпті қазақ мәтіндерінде таңбаланбайтын болады. Программа жіңішкелік және айыру (жуан) белгілерін жоғарыдағы нұсқаулық кестеге сәйкес автоматты түрде алып тастап отырады.
Э және Ё әрпі бар сөздер түгелімен Е таңбасына ауыстырылады.
Ю әрпі – ɪý болып, сол сияқты Я әрпі – ɪa болып екі әріппен таңбаланатындығы орфографиялық емле ережелерінде бекітіліп отыр. Осы ретте программа да осы нұсқаулық кестеге сәйкес мәтінде кездескен Я, Ю әріптерін екі таңбамен аударым жасайтын болады.
Қазақ тілінде Ц әрпі тек қана кірме сөздерде, терминдерде ғана кездеседі. Бұл әріп ұлттық әліпбиге енгізілмеген. Алайда бұл әріп терминдерде кездесетіндіктен, орфографиялық емле жасаушылар оны қалайда таңбалау мақсатында ұлттық әліпбидегі S әрпімен беруді жөн санап отыр. Қазақ тілінде термин ретінде қолданысқа еніп кеткен пицца, ницца сөздерінде Ц әрпі екі рет кездесетіндіктен, мұндай жағдайда ts диграфымен беру көрсетіледі. Ал қалған жағдайлардың барлығында Ц әрпі бір ғана S-мен таңбаланады. Осы орфографиялық емлеген сәйкес, жоғарыдағы кестедегі нұсқаулықта көрсетілгенде, конвертер бағдарламасы пицца және ницца сөздерінен басқа мәтінде кездесетін Ц әрпі бар сөздерде оны S-ға көшіреді. Программаға пицца және ницца сөздері қалыс жағдай (исключение) ретінде көрсетіледі.
Емле ережелерін жасау кезеңінде мамандар Ц әрпін сөз басында бір S-мен, сөз ортасында диграф (ts ) етіп (қос әріппен) таңбалауды да жоспарлаған болатын. Бірақ бұл кейін өзгертілгендіктен, біздің программаға да соған сәйкес өзгеріс енгізілді.
Щ әрпі қазақ тілінің байырғы сөздерінде тек ащы, тұщы сөздерінде ғана қолданылады. Ал негізінен орыс тілінен енген кірме сөздерде кездеседі. Емле жасаушы тілші-мамандар ащы, тұщы сөздерінде Щ-ны екі қосарлама диграфпен (shsh) беруді, ал кірме сөздерде бір ғана диграфпен (sh) беруді шешіп отыр.
Бұл жоғарыда айтылғандардың барлығы негізінен әліпбидегі әріптерді таңбалауға қажетті нұсқаулықтар болып табылады. Яғни кестеге салынған таңбалар арқылы программа кирил қаріптерін латын графикасына ауыстырып шығады.
Үшінші қадам. Мәтінде автоматты аударым жасауда жоғарыда айтылғандан басқа да программаға арналған емле ережелерін жасау қажет. Солардың бірі – таратып жазу шешіліп отырған Я және Ю әріптеріне қатысты.
Қазақ тілінде я, ю (йа, йу (йұу) төл әріптері болмаса да, кезінде кирилл қарпінің енуімен бірге, бір әріппен таңбаланған болатын. Қазір латын графикасына көшіруде бұл әріптер екіге ажыратылып таңбаланатын болғандықтан, осы екі әріп кездесетін кейбір сөздерді автоматты түрде латынға ауыстыруда мынадай жағдайларды ескеру керек болады. Мәселен, бұл екі әріптің құрамында да и әрпі бар және қазақ тілінде осы я, ю әріптерінің алдынан и әрпі жазылатын сөздер бар. Егер я, ю әріптерін иа – ɪa, иу – ɪŷ деп таратып жазатын болса, мұндай сөздерде екі и (ɪ) әрпі қатар келіп қалады. Мұндай жағдайда орфографист-мамандар емледе бір и-ді ғана қалдыруды ұсынып отыр. Осыған сәйкес программаға мынадай ереже беріледі:
«Егер кирилл қарпіндегі мәтіндерде я әрпі бар сөздердің алдында и әрпі кездессе, латын қарпіне ауыстырғанда бір ғана и (ɪ) таңбаланады».
Мысалы: қиял. Егер біз осы сөзді автоматты түрде латынға аударым жасайтын болсақ, qɪɪal болып орфограммаланған болар еді. Мұндай сөздерде и (ɪ) әрпін екі рет жазудың қажеті болмайды. Бұл сөздің дұрыс латынша таңбалану нұсқасы qɪal болады. Осы сияқты ия әріптерімен келген сөздердің барлығын конвертор ɪa етіп таңбалайтын болады.
Осы сияқты ю әрпіне қатысты мынадай ереже-нұсқаулық беріледі:
«Егер кирилл қарпіндегі мәтіндерде ю әрпі бар сөздердің алдында и әрпі кездессе, латын қарпіне ауыстырғанда бір ғана и (ɪ) таңбаланады».
Мысалы: қию. Егер біз осы сөзді автоматты түрде латынға аударым жасайтын болсақ, qɪɪŷ болып орфограммаланған болар еді. Мұндай сөздерде и (ɪ) әрпін екі рет жазудың қажеті болмайды. Бұл сөздің дұрыс латынша таңбалану нұсқасы qɪŷ болады. Осы сияқты ию әріптерімен келген сөздердің барлығын конвертор ɪŷ етіп таңбалайтын болады.
Программа әзірлемесі Visual Studio 2017 ортасында, программалаудың C# тілінде жасалды. Бұл программа латынға көшірудің 2-ші мәрте жасалған нұсқасы болып табылады. Кирилл қаріптерінен латын қарпіне автоматты аударым жасауда DIC сөздігі жасалды. Мұнда кирилл қарпіндегі әрбір әріптің латын баламасы екінші кестеде сәйкесетендіріліп беріледі.
Программа алгоритмі төмендегіше жұмыс жасайды. Енгізілген мәтін алдымен сөйлемдерге бөлінеді, содан кейін сөйлемдер сөздерге, ең соңынан сөздер әріптерге бөлінеді. Осыдан кейін әрбір әріп латындағы сәйкес қаріппен ауыстырылады. Программа алгоритмі келешекте ауыстыру ережелері бойынша жетілдіріледі.
Программаны енгізер кезде екі терезесі бар мәтін енгізу экраны ашылады. Сурет 1.
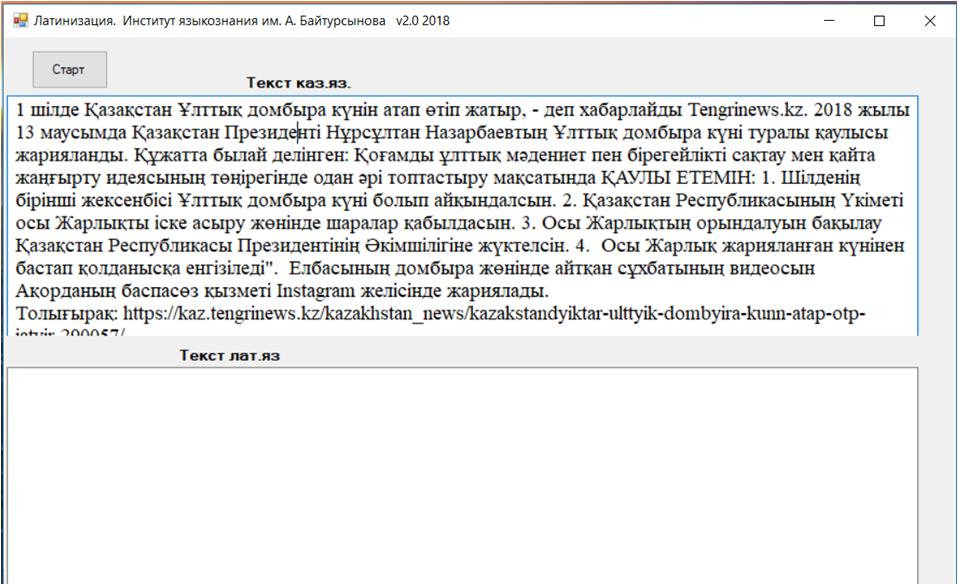
Сурет 1 – Кирилл қарпінен автоматты аударым жасайтын компьютерлік бағдарлама терезесі
Жоғарғы терезеге латынға көшірілуге тиісті кирилл қаріпті қазақ мәтіні енгізіледі. Содан соң «СТАРТ» түймешесі басылады. Осы кезде астыңғы терезеден латын қ аріпті қазақ мәтіні шығады. Сурет 2.
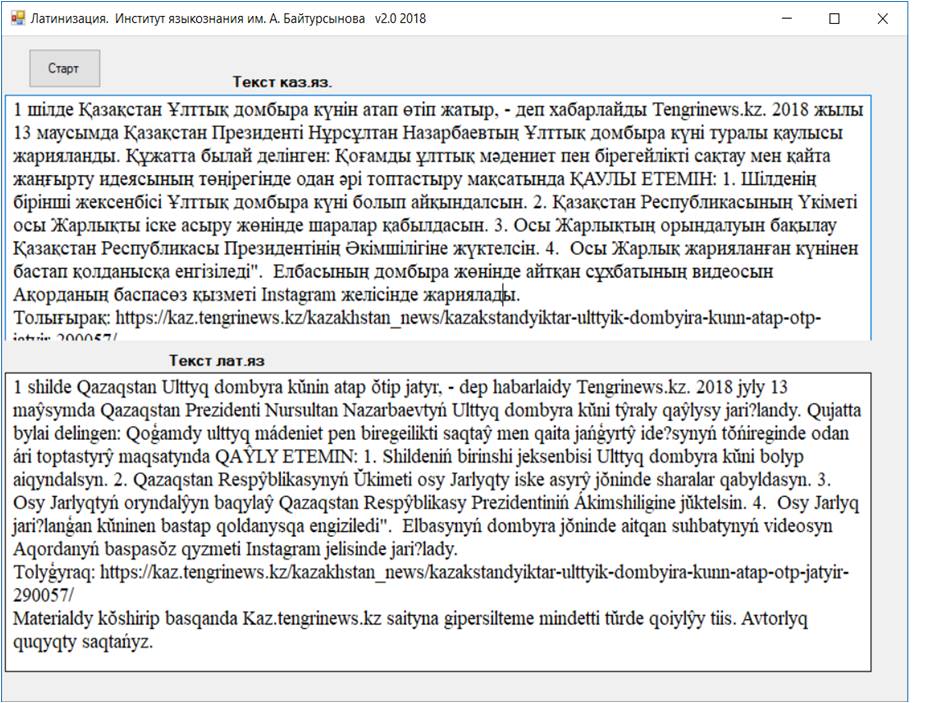
Сурет 2 – Латынға көшіру программасы
Бұл бағдарлама v1.0 программасының бірінші нұсқасы болып табылады. Келешекте қазақ тіліндегі емле ережелеріне сәйкес жетілдіріледі, сонымен қатар осы бағдарлама бойынша көлемді файлдарды салу мен көшірудің бағдарламалары жасалады.
Сонымен тілтанушы мен бағдарламашының бірлескен жұмысының нәтижесінде соңғы акут әліпбиімен соңғы (қазіргі) жасалып жатқан емле-ережелері негізге алынған кирилл қарпіндегі қазақ мәтіндерді автоматты түрде латын графикасына ауыстыратын IT-қосымша жасалды. Бағдарлама институттың латын бойынша жоспарларын жүзеге асыруға өз септігін тигізуде.
А.Ә. Жаңабекова
А.Байтұрсынұлы атындағы Тіл білімі институты
Қолданбалы лингвистика бөлімінің меңгерушісі, ф.ғ.д.
Қ. Қойбағаров
программист
Арнайы Ұлт порталы үшін